Ziel ist es, Europas digitale Souveränität zu stärken und insbesondere deutschen Behörden und Institutionen den Zugang zu leistungsfähiger GenAI-Technologie zu ermöglichen. Ein erster Meilenstein ist das Sprachmodell Teuken-7B, entwickelt unter der Leitung der Fraunhofer-Institute IAIS und IIS und seit November 2024 unter einer Open-Source-Lizenz verfügbar. In dieser Podcast-Folge „Ausgesprochen digital“ sprechen wir über die Bedeutung dieses Projekts und den Weg zu KI „Made in Europe“.
Im Gespräch mit Dr. Nicolas Flores-Herr und Dr. Thomas Wächter
Nicolas Flores-Herr ist Teamleiter Foundation Models & Gen AI Systems und Standortleiter des Fraunhofer-Instituts für Intelligente Analyse- und Informationssysteme (IAIS) in Dresden. Er bringt umfassende Expertise in der Entwicklung intelligenter Dialogsysteme für die Wirtschaft mit – darunter Sprachassistenten, Chat- und Schreibbots, die einen schnellen, intuitiven Zugang zu Informationen ermöglichen.
Sein Fokus liegt auf Lösungen, die nicht nur leistungsfähig, sondern auch datenschutzkonform und kulturell auf den europäischen Raum zugeschnitten sind. Als Projektleiter für OpenGPT-X arbeitet er maßgeblich daran, große KI-Sprachmodelle „Made in Europe“ zu entwickeln und als Open Source verfügbar zu machen.
Thomas Wächter ist Head of AI & Natural Language Processing bei der Telekom MMS und verantwortet ein Expertenteam, das KI-basierte Dienste und Lösungen für Unternehmen in Deutschland entwickelt. Mit über 20 Jahren Erfahrung in den Bereichen Text Mining, NLP, Künstliche Intelligenz und semantischen Technologien schafft er praxisnahen Mehrwert aus Daten und Sprache.
Er arbeitet eng mit führenden Forschungs- und Innovationspartnern zusammen, um neueste Entwicklungen in der generativen KI in marktfähige Anwendungen zu überführen. In OpenGPT-X und dem Modell Teuken-7B sieht er eine Schlüsselressource für vertrauenswürdige KI-Anwendungen in verschiedensten Branchen.
Von Anfang an: Die Entstehung von OpenGPT-X
Im Sommer 2021 wurde der Grundstein für OpenGPT-X gelegt: Ein Konsortium unter der Leitung der Fraunhofer-Institute IAIS und IIS reichte einen Forschungsantrag beim Bundesministerium für Wirtschaft und Klimaschutz (BMWK) ein – mit dem Ziel, leistungsfähige, offene KI-Sprachmodelle „Made in Europe“ zu entwickeln. Der Projektstart im Januar 2022 fiel in eine Zeit wachsender gesellschaftlicher Aufmerksamkeit für generative KI, die mit dem „ChatGPT-Moment“ im Herbst desselben Jahres einen Höhepunkt erreichte.
Mit Teuken-7B veröffentlichte das Konsortium – zu dem u. a. TU Dresden, DFKI, Forschungszentrum Jülich und weitere Partner zählen – im November 2024 das erste große Sprachmodell des Projekts. Es wurde auf dem Jülicher Supercomputer JUWELS trainiert, ist vollständig quelloffen (Apache 2.0) und optimiert für den Einsatz in allen 24 EU-Amtssprachen. Damit leistet OpenGPT-X einen wichtigen Beitrag zur digitalen Souveränität Europas und setzt neue Maßstäbe für verantwortungsvolle KI-Anwendungen.
Teuken-7B- Ein Open-Source-Sprachmodell mit europäischen Stärken
Teuken-7B ist mehr als nur ein großes KI-Sprachmodell – es ist ein strategisches Werkzeug für digitale Souveränität, Innovation und vertrauenswürdige Anwendungen in Europa. Es vereint Offenheit, Anpassbarkeit und Effizienz. Seine Besonderheiten und Potenziale im Überblick:
- Offen für alle: Open Source als Innovationsmotor. Mit über 60.000 Downloads in kürzester Zeit zeigt Teuken-7B, wie kraftvoll eine engagierte Community wirken kann. Die Veröffentlichung unter Apache-2.0-Lizenz ermöglicht die freie Nutzung, Weiterentwicklung und Integration – auch für kommerzielle Zwecke. Unternehmen können das Modell vollständig an eigene Anforderungen anpassen, ohne auf proprietäre Black-Box-Technologie angewiesen zu sein.
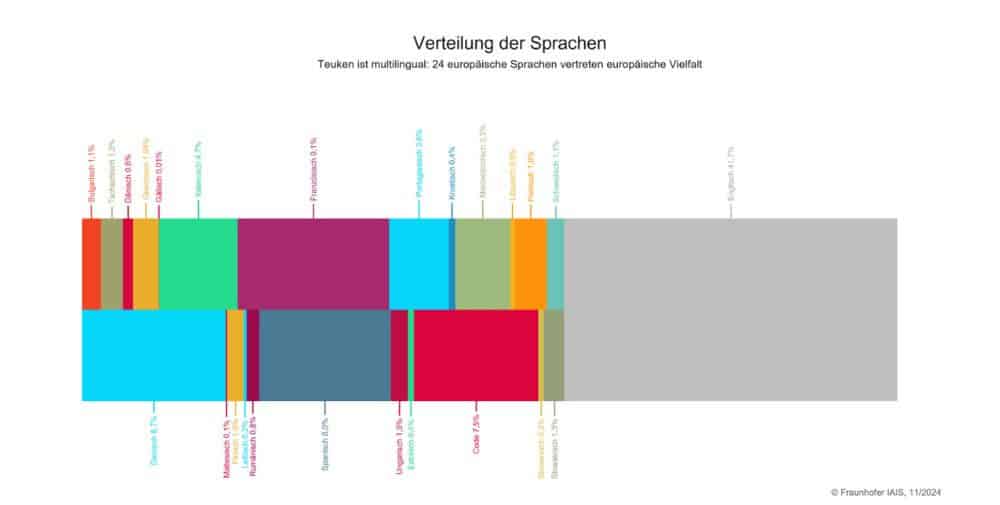
- Multilingual von Grund auf: Für ein diverses Europa gebaut. Im Gegensatz zu vielen existierenden Modellen wurde Teuken-7B konsequent multilingual trainiert – auf allen 24 EU-Amtssprachen und mit 50 % nicht-englischen Trainingsdaten. Das sorgt für stabile Leistung über Sprachgrenzen hinweg und ermöglicht zuverlässige KI-Anwendungen für international tätige Unternehmen und Institutionen.
- Maßgeschneidert statt von der Stange: Anpassbarkeit inklusive. Mit Instruction Tuning für dialogbasierte Nutzung und offenem Zugang zur Architektur können Organisationen Teuken-7B für ihre spezifischen Szenarien trainieren – ob für Kundenservice, Wissensmanagement oder Fachanwendungen mit sensiblen Inhalten. Auch sicherheitskritische Einsatzbereiche wie Robotik, Automobilindustrie oder Medizin profitieren von der vollständigen Kontrolle über Modell und Daten.
- Effizienz trifft Leistung: Europäischer Tokenizer als Gamechanger. Dank eines eigens entwickelten Tokenizers arbeitet Teuken-7B energie- und kosteneffizienter als viele andere Sprachmodelle – besonders bei komplexen europäischen Sprachen wie Deutsch, Finnisch oder Ungarisch. Diese technologische Grundlage wurde im Projekt gezielt erforscht, um nachhaltige und leistungsstarke KI-Anwendungen zu ermöglichen.
- Vertrauen durch Transparenz: Nachvollziehbare Herkunft, klare Standards. Die Trainingsdaten wurden hinsichtlich ihrer lizenzrechtlichen Nutzung für die Veröffentlichung eingehend geprüft, um sicherzustellen, dass die verwendeten Daten für das Modelltraining verwendet werden dürfen. Dieses Vorgehen ist ein wichtiger Aspekt im Kontext des European AI Acts.
Bewertung von KI-Modellen: Warum Größe nicht alles ist
Die Größe eines Modells ist nicht automatisch ein Qualitätsmerkmal. Entscheidend ist, wie gut es zu den konkreten Anforderungen passt. Teuken-7B beweist, dass ein schlankes, transparentes Modell mit europäischen Werten nicht nur eine leistungsfähige Alternative, sondern in vielen Fällen die überlegene Wahl sein kann.
Anwendungsbereiche und Hostingmöglichkeiten von Teuken-7B: Flexibilität trifft auf Datensouveränität
Teuken-7B ist ein vielseitiges und anpassungsfähiges KI-Modell, das Unternehmen in verschiedenen Branchen einsetzen können. Ob für Textanalyse, Dokumentenmanagement oder semantische Suche – das Modell bietet maßgeschneiderte Lösungen, die durch Finetuning auf branchenspezifische Anforderungen zugeschnitten werden können. Besonders in der Dokumentenanalyse und im Wissensmanagement ermöglicht Teuken-7B durch Retrieval Augmented Generation (RAG) eine gezielte und effiziente Verarbeitung großer Datenmengen.
- AI Foundation Services: Sicherheit und Skalierbarkeit auf höchstem Niveau.
Mit den AI Foundation Services bietet die Telekom-Tochter T-Systems ein umfassendes Angebot an Betriebsmodellen, die speziell auf die Bedürfnisse europäischer Unternehmen und Behörden abgestimmt sind. Teuken-7B kann in hochsicheren, DSGVO-konformen Rechenzentren in Deutschland und Europa betrieben werden, oder sogar auf dedizierter Infrastruktur beim Kunden vor Ort – ideal für sensible und besonders schützenswerte Daten. Diese Flexibilität ist besonders wichtig für Unternehmen in regulierten Branchen wie dem Finanzsektor, der Gesundheitsbranche oder dem öffentlichen Sektor, die höchste Ansprüche an Sicherheit und Compliance stellen. Die AI Foundation Services bieten Unternehmen so die Möglichkeit generative KI-Anwendungen auf skalierbaren, sicheren Plattformen zu entwickeln und zu betreiben.
- Business GPT: Integrierte KI-Lösungen für Unternehmen.
Teuken-7B ist direkt in das standardisierte Telekom-Produkt Business GPT integriert, das „out-of-the-box“ RAG-Anwendungen und Funktionen zur Verarbeitung von Dokumenten und internen Unternehmens-Chats bereitstellt. Über eine einheitliche API können Unternehmen das Modell nahtlos in bestehende KI-Assistenten, Agenten und Chatbots integrieren und so schnell von der Leistungsfähigkeit generativer KI profitieren.
Zukunftsperspektiven: Weiterentwicklung und Herausforderungen
Die Reise von OpenGPT-X und Teuken-7B ist nur der Anfang einer spannenden Entwicklung im Bereich der generativen KI. Das Konsortium wird weiterhin an der Verbesserung und Erweiterung der Modellvarianten arbeiten. Nicolas Flores-Herr betont, dass die kontinuierliche Forschung darauf abzielt, die Leistungsfähigkeit und Anpassungsfähigkeit der Modelle weiter zu steigern. Zukünftige Entwicklungen könnten Modelle hervorbringen, die nicht nur in der Breite anwendbar sind, sondern auch in der Tiefe auf spezifische Branchenbedürfnisse abgestimmt werden.
Ein wichtiger Fokus liegt auf der Integration multimodaler Datentypen wie Text, Bild und Audio. Diese Entwicklung könnte die KI-Modelle von OpenGPT-X noch leistungsfähiger machen und eine breitere Palette von Anwendungen ermöglichen, die über reine Textverarbeitung hinausgehen. Thomas Wächter hebt hervor, dass durch die Integration dieser Datentypen KI-Systeme in der Lage sein könnten, noch umfassendere und kontextualisierte Antworten zu liefern – etwa in Bereichen wie Medienanalyse, Produktentwicklung oder medizinischer Diagnostik.
Ein weiteres zentrales Thema ist und bleibt die Datensouveränität und die Erklärbarkeit von KI-Modellen. Besonders vor dem Hintergrund des EU-AI-Acts wird die Transparenz und Nachvollziehbarkeit von Modellen immer wichtiger. OpenGPT-X setzt hier mit seiner offenen Struktur neue Maßstäbe. Welche weiteren Entwicklungen und Potenziale sich hier ergeben, gibt es in dieser Podcast-Folge zu hören. Wie wünschen gute Unterhaltung!
Moderiert wird diese Folge von Steffen Wenzel, Mitgründer und Geschäftsführer von politik-digital und Stefanie Liße, Senior Sales Managerin bei Telekom MMS.
– – – – –
Weiterführende Links
👉 www.telekom-mms.com
👉 Zum Podcast „KI ‚Made in Germany‘: Wie OpenGPT-X zur digitalen Souveränität Europas beiträgt“
👉 Telekom bietet Sprachmodell ‚Made in Germany‘ von OpenGPT-X an
Grafik: Telekom MMS